






This text is a part of VentureBeat’s particular subject, “The Actual Value of AI: Efficiency, Effectivity and ROI at Scale.” Learn extra from this particular subject.
AI pilots not often begin with a deep dialogue of infrastructure and {hardware}. However seasoned scalers warn that deploying high-value manufacturing workloads won’t finish fortunately with out strategic, ongoing concentrate on a key enterprise-grade basis.
Excellent news: There’s rising recognition by enterprises in regards to the pivotal position infrastructure performs in enabling and increasing generative, agentic and different clever functions that drive income, value discount and effectivity good points.
In keeping with IDC, organizations in 2025 have boosted spending on compute and storage {hardware} infrastructure for AI deployments by 97% in comparison with the identical interval a 12 months earlier than. Researchers predict world funding within the area will surge from $150 billion immediately to $200 billion by 2028.
However the aggressive edge “doesn’t go to those that spend probably the most,” John Thompson, best-selling AI creator and head of the gen AI Advisory apply at The Hackett Group stated in an interview with VentureBeat, “however to those that scale most intelligently.”
Ignore infrastructure and {hardware} at your personal peril
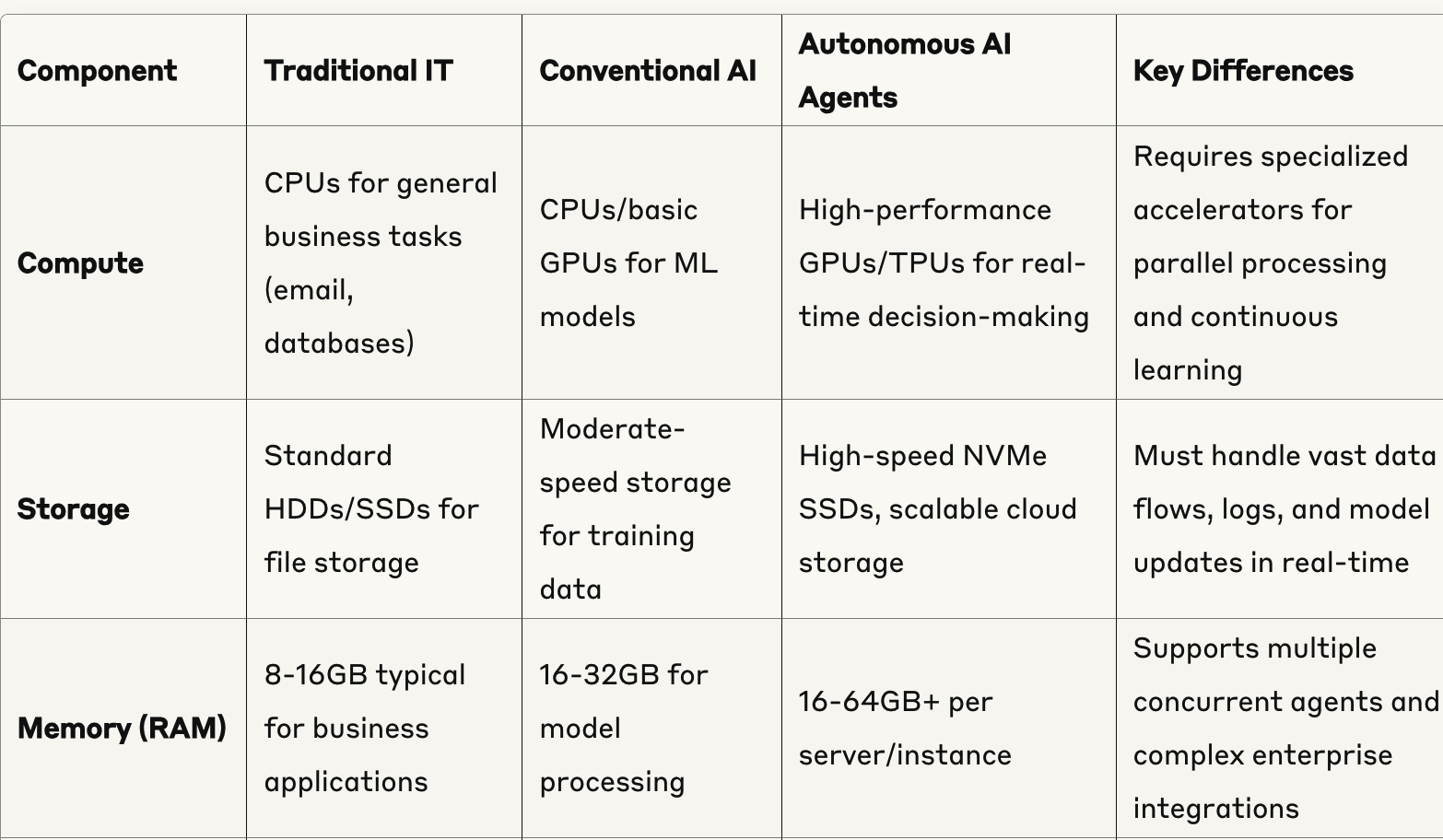
Different consultants agree, saying that likelihood is slim-to-none that enterprises can increase and industrialize AI workloads with out cautious planning and right-sizing of the finely orchestrated mesh of processors and accelerators, in addition to upgraded energy and cooling programs. These purpose-built {hardware} elements present the velocity, availability, flexibility and scalability required to deal with unprecedented information quantity, motion and velocity from edge to on-prem to cloud.
Supply: VentureBeat
Research after research identifies infrastructure-related points, reminiscent of efficiency bottlenecks, mismatched {hardware} and poor legacy integration, alongside information issues, as main pilot killers. Exploding curiosity and funding in agentic AI additional increase the technological, aggressive and monetary stakes.
Amongst tech corporations, a bellwether for the complete trade, practically 50% have agent AI initiatives underway; the remaining can have them moving into 24 months. They’re allocating half or extra of their present AI budgets to agentic, and lots of plan additional will increase this 12 months. (Good factor, as a result of these advanced autonomous programs require expensive, scarce GPUs and TPUs to function independently and in actual time throughout a number of platforms.)
From their expertise with pilots, expertise and enterprise leaders now perceive that the demanding necessities of AI workloads — high-speed processing, networking, storage, orchestration and immense electrical energy — are in contrast to something they’ve ever constructed at scale.
For a lot of enterprises, the urgent query is, “Are we prepared to do that?” The sincere reply can be: Not with out cautious ongoing evaluation, planning and, seemingly, non-trivial IT upgrades.
They’ve scaled the AI mountain — hear
Like snowflakes and youngsters, we’re reminded that AI initiatives are related but distinctive. Calls for differ wildly between numerous AI features and kinds (coaching versus inference, machine studying vs reinforcement). So, too, do vast variances exist in enterprise objectives, budgets, expertise debt, vendor lock-in and accessible expertise and capabilities.
Predictably, then, there’s no single “finest” strategy. Relying on circumstances, you’ll scale AI infrastructure up or horizontally (extra energy for elevated masses), out or vertically (upgrading current {hardware}) or hybrid (each).
Nonetheless, these early-chapter mindsets, ideas, suggestions, practices, real-life examples and cost-saving hacks will help maintain your efforts aimed and transferring in the precise path.
It’s a sprawling problem, with a number of layers: information, software program, networking, safety and storage. We’ll maintain the main focus high-level and embrace hyperlinks to useful, associated drill-downs, reminiscent of these above.
Modernize your imaginative and prescient of AI infrastructure
The most important mindset shift is adopting a brand new conception of AI — not as a standalone or siloed app, however as a foundational functionality or platform embedded throughout enterprise processes, workflows and instruments.
To make this occur, infrastructure should steadiness two necessary roles: Offering a steady, safe and compliant enterprise basis, whereas making it straightforward to rapidly and reliably area purpose-built AI workloads and functions, usually with tailor-made {hardware} optimized for particular domains like pure language processing (NLP) and reinforcement studying.
In essence, it’s a serious position reversal, stated Deb Golden, Deloitte’s chief innovation officer. “AI have to be handled like an working system, with infrastructure that adapts to it, not the opposite method round.”
She continued: “The long run isn’t nearly subtle fashions and algorithms. {Hardware} is now not passive. [So from now on], infrastructure is basically about orchestrating clever {hardware} because the working system for AI.”
To function this manner at scale and with out waste requires a “fluid material,” Golden’s time period for the dynamic allocation that adapts in real-time throughout each platform, from particular person silicon chips as much as full workloads. Advantages will be enormous: Her crew discovered that this strategy can minimize prices by 30 to 40% and latency by 15 to twenty%. “In case your AI isn’t respiratory with the workload, it’s suffocating.”
It’s a demanding problem. Such AI infrastructure have to be multi-tier, cloud-native, open, real-time, dynamic, versatile and modular. It must be extremely and intelligently orchestrated throughout edge and cellular units, on-premises information facilities, AI PCs and workstations, and hybrid and public cloud environments.
What feels like buzzword bingo represents a brand new epoch within the ongoing evolution, redefining and optimizing enterprise IT infrastructure for AI. The primary components are acquainted: hybrid environments, a fast-growing universe of more and more specialised cloud-based companies, frameworks and platforms.
On this new chapter, embracing architectural modularity is essential for long-term success, stated Ken Englund, EY Americas expertise development chief. “Your capacity to combine totally different instruments, brokers, options and platforms can be important. Modularity creates flexibility in your frameworks and architectures.”
Decoupling programs elements helps future-proof in a number of methods, together with vendor and expertise agnosticism, lug-and-play mannequin enhancement and steady innovation and scalability.
Infrastructure funding for scaling AI should steadiness prudence and energy
Enterprise expertise groups seeking to increase their use of enterprise AI face an up to date Goldilocks problem: Discovering the “excellent” funding ranges in new, fashionable infrastructure and {hardware} that may deal with the fast-growing, shifting calls for of distributed, in all places AI.
Beneath-invest or persist with present processing capabilities? You’re taking a look at show-stopping efficiency bottlenecks and subpar enterprise outcomes that may tank whole initiatives (and careers).
Over-invest in shiny new AI infrastructure? Say hiya to huge capital and ongoing working expenditures, idle assets and operational complexity that no one wants.
Much more than in different IT efforts, seasoned scalers agreed that merely throwing processing energy at issues isn’t a successful technique. But it stays a temptation, even when not totally intentional.
“Jobs with minimal AI wants usually get routed to costly GPU or TPU infrastructure,” stated Mine Bayrak Ozmen, a change veteran who’s led enterprise AI deployments at Fortune 500 corporations and a Heart of AI Excellence for a serious world consultancy.
Satirically, stated Ozmen, additionally co-founder of AI platform firm Riernio, “it’s just because AI-centric design decisions have overtaken extra classical group ideas.” Sadly, the long-term value inefficiencies of such deployments can get masked by deep reductions from {hardware} distributors, she stated.
Proper-size AI infrastructure with correct scoping and distribution, not uncooked energy
What, then, ought to information strategic and tactical decisions? One factor that shouldn’t, consultants agreed, is a paradoxically misguided reasoning: As a result of infrastructure for AI should ship ultra-high efficiency, extra highly effective processors and {hardware} have to be higher.
“AI scaling is not about brute-force compute,” stated Hackett’s Thompson, who has led quite a few giant world AI initiatives and is the creator of The Path to AGI: Synthetic Common Intelligence: Previous, Current, and Future, printed in February. He and others emphasize that the aim is having the precise {hardware} in the precise place on the proper time, not the most important and baddest in all places.
In keeping with Ozmen, profitable scalers make use of “a right-size for right-executing strategy.” Meaning “optimizing workload placement (inference vs. coaching), managing context locality, and leveraging policy-driven orchestration to scale back redundancy, enhance observability and drive sustained development.”
Typically the evaluation and choice are back-of-a-napkin easy. “A generative AI system serving 200 workers may run simply fantastic on a single server,” Thomspon stated. But it surely’s a complete totally different case for extra advanced initiatives.
Take an AI-enabled core enterprise system for a whole lot of hundreds of customers worldwide, requiring cloud-native failover and critical scaling capabilities. In these instances, Thompson stated, right-sizing infrastructure calls for disciplined, rigorous scoping, distribution and scaling workouts. Anything is foolhardy malpractice.
Surprisingly, such fundamental IT planning self-discipline can get skipped. It’s usually corporations, determined to realize a aggressive benefit, that attempt to velocity up issues by aiming outsized infrastructure budgets at a key AI challenge.
New Hackett analysis challenges some fundamental assumptions about what is really wanted in infrastructure for scaling AI, offering extra causes to conduct rigorous upfront evaluation.
Thompson’s personal real-world expertise is instructive. Constructing an AI buyer help system with over 300,000 customers, his crew quickly realized it was “extra necessary to have world protection than huge capability in any single location.” Accordingly, infrastructure is positioned throughout the U.S., Europe and the Asia-Pacific area; customers are dynamically routed worldwide.
The sensible takeaway recommendation? “Put fences round issues. Is it 300,000 customers or 200? Scope dictates infrastructure,” he stated.
The correct {hardware} in the precise place for the precise job
A contemporary multi-tiered AI infrastructure technique depends on versatile processors and accelerators that may be optimized for numerous roles throughout the continuum. For useful insights on selecting processors, take a look at Going Past GPUs.
Supply: VentureBeat
Sourcing infrastructure for AI scaling: cloud companies for many
You’ve obtained a contemporary image of what AI scaling infrastructure can and must be, a good suggestion in regards to the funding candy spot and scope, and what’s wanted the place. Now it’s time for procurement.
As famous in VentureBeat’s final particular subject, for many enterprises, the best technique can be to proceed utilizing cloud-based infrastructure and tools to scale AI manufacturing.
Surveys of enormous organizations present most have transitioned from customized on-premises information facilities to public cloud platforms and pre-built AI options. For a lot of, this represents a next-step continuation of ongoing modernization that sidesteps large upfront capital outlays and expertise scrambles whereas offering important flexibility for rapidly altering necessities.
Over the subsequent three years, Gartner predicts ,50% of cloud compute assets can be dedicated to AI workloads, up from lower than 10% immediately. Some enterprises are additionally upgrading on-premises information facilities with accelerated compute, quicker reminiscence and high-bandwidth networking.
The excellent news: Amazon, AWS, Microsoft, Google and a booming universe of specialty suppliers proceed to speculate staggering sums in end-to-end choices constructed and optimized for AI, together with full -stack infrastructure, platforms, processing together with GPU cloud suppliers, HPC, storage (hyperscalers plus Dell, HPE, Hitachi Vantara), frameworks and myriad different managed companies.
Particularly for organizations eager to dip their toes rapidly, stated Wyatt Mayham, lead AI marketing consultant at Northwest AI Consulting, cloud companies supply an incredible, low-hassle alternative.
In an organization already working Microsoft, for instance, “Azure OpenAI is a pure extension [that] requires little structure to get working safely and compliantly,” he stated. “It avoids the complexity of spinning up customized LLM infrastructure, whereas nonetheless giving corporations the safety and management they want. It’s an incredible quick-win use case.”
Nonetheless, the bounty of choices accessible to expertise decision-makers has one other aspect. Deciding on the suitable companies will be daunting, particularly as extra enterprises go for multi-cloud approaches that span a number of suppliers. Problems with compatibility, constant safety, liabilities, service ranges and onsite useful resource necessities can rapidly develop into entangled in a posh net, slowing improvement and deployment.
To simplify issues, organizations might determine to stay with a main supplier or two. Right here, as in pre-AI cloud internet hosting, the hazard of vendor lock-in looms (though open requirements supply the potential of alternative). Hanging over all that is the specter of previous and up to date makes an attempt emigrate infrastructure to paid cloud companies, solely to find, with horror, that prices far surpass the unique expectations.
All this explains why consultants say that the IT 101 self-discipline of realizing as clearly as attainable what efficiency and capability are wanted – on the edge, on-premises, in cloud functions, in all places – is essential earlier than beginning procurement.
Take a contemporary take a look at on-premises
Standard knowledge means that dealing with infrastructure internally is primarily reserved for deep-pocketed enterprises and closely regulated industries. Nonetheless, on this new AI chapter, key in-house components are being re-evaluated, usually as a part of a hybrid right-sizing technique.
Take Microblink, which supplies AI-powered doc scanning and identification verification companies to purchasers worldwide. Utilizing Google Cloud Platform (GCP) to help high-throughput ML workloads and data-intensive functions, the corporate rapidly bumped into points with value and scalability, stated Filip Suste, engineering supervisor of platform groups. “GPU availability was restricted, unpredictable and costly,” he famous.
To handle these issues, Suste’s groups made a strategic shift, transferring pc workloads and supporting infrastructure on-premises. A key piece within the shift to hybrid was a high-performance, cloud-native object storage system from MinIo.
For Microblink, taking key infrastructure again in-house paid off. Doing so minimize associated prices by 62%, lowered idle capability and improved coaching effectivity, the corporate stated. Crucially, it additionally regained management over AI infrastructure, thereby bettering buyer safety.
Think about a specialty AI platform
Makino, a Japanese producer of computer-controlled machining facilities working in 40 international locations, confronted a traditional expertise hole downside. Much less skilled engineers might take as much as 30 hours to finish repairs that extra seasoned employees can do in eight.
To shut the hole and enhance customer support, management determined to show twenty years of upkeep information into immediately accessible experience. The quickest and most cost-effective resolution, they concluded, is to combine an current service-management system with a specialised AI platform for service professionals from Aquant.
The corporate says taking the simple expertise path produced nice outcomes. As a substitute of laboriously evaluating totally different infrastructure eventualities, assets had been centered on standardizing lexicon and growing processes and procedures, Ken Creech, Makino’s director of buyer help, defined.
Distant decision of issues has elevated by 15%, resolution occasions have decreased, and clients now have self-service entry to the system, Creech stated. “Now, our engineers ask a plain-language query, and the AI hunts down the reply rapidly. It’s a giant wow issue.”
Undertake conscious cost-avoidance hacks
At Albertsons, one of many nation’s largest meals and drug chains, IT groups make use of a number of easy however efficient techniques to optimize AI infrastructure with out including new {hardware}, stated Chandrakanth Puligundla, tech lead for information evaluation, engineering and governance.
Gravity mapping, for instance, reveals the place information is saved and the way it’s moved, whether or not on edge units, inner programs or on multi-cloud programs. This data not solely reduces egress prices and latency, Puligundla defined, however guides extra knowledgeable choices about the place to allocate computing assets.
Equally, he stated, utilizing specialist AI instruments for language processing or picture identification takes much less area, usually delivering higher efficiency and economic system than including or updating dearer servers and general-purpose computer systems.
One other cost-avoidance hack: Monitoring watts per inference or coaching hour. Trying past velocity and value to energy-efficiency metrics prioritizes sustainable efficiency, which is essential for more and more power-thirsty AI fashions and {hardware}.
Puligundla concluded: “We will actually enhance effectivity via this sort of conscious preparation.”
Write your personal ending
The success of AI pilots has introduced hundreds of thousands of corporations to the subsequent section of their journeys: Deploying generative and LLMs, brokers and different clever functions with excessive enterprise worth into wider manufacturing.
The most recent AI chapter guarantees wealthy rewards for enterprises that strategically assemble infrastructure and {hardware} that balances efficiency, value, flexibility and scalability throughout edge computing, on-premises programs and cloud environments.
Within the coming months, scaling choices will increase additional, as trade investments proceed to pour into hyper-scale information facilities, edge chips and {hardware} (AMD, Qualcomm, Huawei), cloud-based AI full-stack infrastructure like Canonical and Guru, context-aware reminiscence, safe on-prem plug-and-play units like Lemony, and far more.
How correctly IT and enterprise leaders plan and select infrastructure for growth will decide the heroes of firm tales and the unfortunates doomed to pilot purgatory or AI damnation.

